これまで培った画像認識エッジAI技術を活かし、オンプレミス提供の生成AIと組み合わせることで、エッジ処理による即時性と高セキュリティを両立し、新たな価値を提供します。
VLMは画像や映像を見て言葉で説明できる最新のAIです。
従来のAIは特定の対象や動作ごとに専用モデルを学習させる必要がありましたが、VLMは映像とテキストを同時に理解できるため、一つの仕組みで多様な状況に柔軟に対応できます。
監視カメラや現場作業映像から人の動きや現場の状況を自動で言語化することで、安全監視や業務効率化を支援します。
工場や施設など幅広い現場で、安全性と効率性を高める新しい価値を提供します。
画像認識エッジソリューションのご紹介 〜 VLMを活用した生成AIソリューション 〜

<従来のAIの課題>

これまで培った組込み機器向け画像認識AIの豊富な開発実績を活かし、お客さまの限られたリソース環境にVLMを活用した生成AIソリューションの提供が可能。
物体を検出し、サーバー上でVLMより状況分析、異常時は言語化して通知
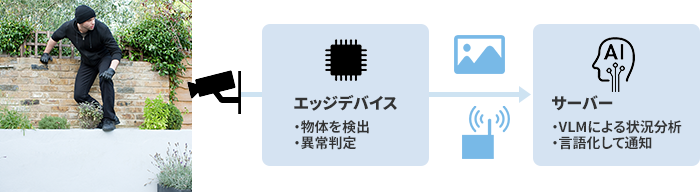

VLMソリューション
PDF(1.6MB)![]()
関連ソリューション
本製品に関するお問い合わせはこちらから
お問い合わせフォームリーフレットのダウンロードはこちらから
資料ダウンロード
